
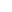

今天介绍的是厦门大学ASC实验室(asc.xmu.edu.cn)近期被IJCAI-24会议接收的一篇论文:「FedPFT: Federated ProxyFine-Tuning of Foundation Models」。国际联合人工智能大会(简称IJCAI)是人工智能领域的顶级学术会议,是CCF A类推荐会议。会议每一年举办一届,IJCAI-24将于2024年8月3-9日在韩国济州岛举行。
针对现有的子模型近似微调大模型方法面临的基座模型微调不充分和梯度误差累积等研究挑战,本文提出了一种面向基座模型的联邦学习代理微调方法(简称FedPFT)。FedPFT采用逐层压缩(Layer-wise compression)神经元的方式构建子模型(sub- FM),并通过两步知识蒸馏过程来减少sub-FM对齐时的梯度误差累计,从而保障了微调后基座模型性能,并避免了直接共享客户端原始数据与服务器端基座模型而造成的数据隐私和模型安全问题。最终,FedPFT在7个文本和视觉数据集上取得SOTA。
1 研究背景与挑战
近年来,多种基于自注意力技术构建的基座模型在计算机视觉、自然语言处理等各个领域的下游任务上取得了显著效果,但也引起了人们对数据隐私和预训练模型版权的担忧。一些现有工作提出了异地微调的方法,通过微调基座模型对应的子模型,并同步子模型的梯度到基座模型,从而近似微调基座模型,避免了客户端原始数据和服务器端预训练基座模型的直接共享。然而,现有方法仍然存在微调后基座模型性能不足的问题,在我们看来,主要存在以下两大影响基座模型性能的挑战:
挑战1:现有方法通过层剪枝压缩(layer-dropcompression)构建子模型,从而丢失了子模型与基座模型之间的重要对应关系,导致基座模型微调不充分。如图 1(a)所示,在现有方法中,子模型中被更新层的梯度将在微调结束后以插入的方式直接同步到基座模型的对应层中,这意味着子模型与基座模型间无对应关系的中间层将无法被微调更新,使得基座模型微调不充分。我们提出的FedPFT方法,通过逐层压缩技术(layer-wise compression)来构建子模型,其优势是保留了子模型与基座模型间的层间对应关系,使得基座模型的所有层都可以借助子模型进行微调,从而保证了微调后基座模型性能。
挑战2:随着联邦微调的进行,子模型和与基座模型之间的差异会逐渐增大,使得基座模型的实际梯度更新方向逐步偏离理想更新方向,导致微调后基座模型性能下降。如图 1(b)所示,现有的借助代理子模型进行微调的方法,其基座模型的更新完全依赖于代理子模型在下游任务上的更新。因此,随着联邦微调的进行,子模型与基座模型之间的差异会逐渐增大,其梯度方向也会逐步偏离理想的更新方向(即使用完整模型微调获得的梯度更新方向)。与之相反,我们提出的FedPFT在联邦微调过程中使用知识蒸馏来使得子模型与基座模型尽量保持一致,从而确保基座模型的精确更新。
图1. 借助代理子模型近似微调基座模型面临的两个挑战
因此,针对上述挑战,本文提出了基座模型的联邦学习代理微调方法(简称FedPFT)。首先,设计了基于逐层压缩的子模型构建模块。通过保留子模型与基座模型之间的层对应关系,确保了基座模型的充分微调,同时缓解了客户端微调基座模型所需的训练开销;其次,提出了基于两步知识蒸馏的子模型对齐模块,即联邦微调过程前的层级别蒸馏和联邦微调过程中的神经元级别蒸馏,并从理论上阐明了借助知识蒸馏对齐子模型对于同类方法的重要意义,以保证基座模型的准确微调。最后,使用三个基座模型(BERT、RoBERTa和ViT)在四个文本和三个图像数据集上开展了基座模型微调的实验。实验结果证明了FedPFT的有效性。本文的研究成果,在客户端计算资源受限和隐私计算场景下,将为闭源基座模型的联邦隐私微调工作提供思路,并赋能行业大模型的落地应用。
2 问题形式化
给定基座模型和下游数据集D。微调旨在获得一个具有解决下游任务能力的新模型
,形式化表示为
,其中
。
问题定义(借助代理子模型的基座模型微调):首先,通过压缩基座模型中的部分参数得到子模型
,其中,
表示压缩函数,即
分别为
的保留部分和被压缩部分参数。其次,在下游任务数据集上微调代理子模型
,且微调时仅更新保留部分(即
)的参数,最后将
部分的更新同步到基座模型
中,以获得
的近似
,形式化表示为
,其中
。
3 FedPFT的总体框架
FedPFT算法总体框架如图 2所示,共包含两个模块:第一,子模型构建模块通过计算每一个transformer层中前馈神经网络(FFN)子层的所有神经元连接权重的二范数,用于衡量神经元显著性,从而剔除掉显著性低的神经元以实现基座模型的逐层压缩;第二,子模型对齐模块分别在联邦微调过程前后使用层级别蒸馏和神经元级别蒸馏进行子模型的对齐,以保障基座模型的精准微调。
图2. FedPFT总体框架
子模型构建模块的具体流程包括:(1)被压缩部分参数选取,通过对transformer层的结构进行分析可以发现transformer层的大部分参数位于其FFN子层中,为了在尽可能减少子模型参数量的同时,保留层间对应关系以使基座模型的每一层都可微调,本文选择对FFN子层进行压缩;(2)神经元显著性衡量,通过对FFN子层的输出表达式进行变换,可以将FFN子层的输出表示为相互独立的所有神经元输出的总和,这意味着连接权重范数越小的神经元的输出对层输出的影响越小,因此,本文使用神经元连接权重的二范数来衡量神经元显著性并据此进行逐层压缩从而构建子模型。相关表达式请见原文。
子模型对齐模块的具体流程包括:(1)层级别蒸馏,为了保证子模型与基座模型之间每一层的前向输出与反向梯度的一致,在联邦微调过程前,使用子模型与基座模型每一层的输出及参数矩阵间的均方误差(MSE)作为蒸馏损失来进行层级别的蒸馏。(2)神经元级别蒸馏,由于服务器端蒸馏数据集和客户端微调数据集通常来自不同域,为了避免蒸馏和微调两个任务间的灾难性遗忘,首先在本地微调过程中通过计算神经元输出的平均零激活百分比(APoZ)来选取出对下游任务学习影响较小的神经元,随后在蒸馏时仅更新这些神经元来进行神经元级别的蒸馏。(3)收敛性分析,本文通过理论分析推导出了借助代理子模型的基座模型微调收敛需要满足的条件,并进一步揭示了蒸馏对于帮助同类方法收敛的重要性。相关公式、定理及证明请见原文3.5节和附录A和B。
4 实验与验证
实验设置:本文使用三个基座模型在七个常用数据集上进行了微调实验。所用模型包括两个自然语言处理模型(BERT、RoBERTa)和一个计算机视觉模型(ViT)。所用数据集包括四个文本数据集(SST-2、QNLI、QQP、MNLI)和三个图像数据集(CIFAR-10、CIFAR-100、Flowers)。更多数据集描述、实验细节设置、基线方法介绍及参数设置,请见原文第4章。
实验结果1. 总体性能对比
表1展示了各种方法使用BERT和RoBERTa在文本数据集上微调获得的实验结果。相比于使用子模型微调的基线方法,FedPFT在参数量相同的情况下性能显著更优。此外,相比于使用完整模型微调的基线方法,FedPFT在不直接共享基座模型且客户端模型参数量更少的情况下性能十分接近,其他模型及数据集实验结果请见原文附录C。
实验结果2. 数据异质性场景下的性能对比
在实际应用中,联邦学习中各个客户端所持有的数据通常并不是独立同分布的,这也会对联邦微调算法的性能造成影响。如表2所示,在数据异质性程度增大的同时,所有方法的性能都有所下降,但FedPFT依然优于使用子模型微调的基线方法,且在部分异质场景下甚至优于使用完整模型微调的基线方法,其他模型及数据集实验结果请见原文附录D和E。
实验结果3. 消融实验
本文还针对FedPFT的两个模块进行了消融实验,分别对逐层压缩构建子模型、联邦微调前对齐、联邦微调中对齐三个部分的有效性进行了实验验证,结果表明了FedPFT各个模块对于提升微调后基座模型性能的影响,表3展示了BERT和RoBERTa上的消融实验结果,其他实验结果请见原文附录F。
实验结果4. 超参设置的影响
本文讨论了两个超参数设置对模型性能的影响,包括蒸馏对齐的时间间隔和蒸馏时需要更新的神经元比例。表4展示了部分实验结果,完整结果请见原文附录G。
5 总结
本文提出了一种新颖的基座模型的联邦学习代理微调方法 FedPFT。FedPFT通过逐层压缩构建子模型,并通过两阶段蒸馏对齐子模型,从而有效解决了现有借助子模型微调基座模型的方法面临的基座模型微调不充分和梯度误差累积的关键研究问题。FedPFT可以在服务器基座模型和客户端原始数据均不直接共享的前提下实现基座模型的下游任务适应,获得具备解决下游任务能力的基座模型。未来,我们将尝试把FedPFT应用到更大的基座模型和更复杂的下游任务中。